
 像素鱼丸
像素鱼丸
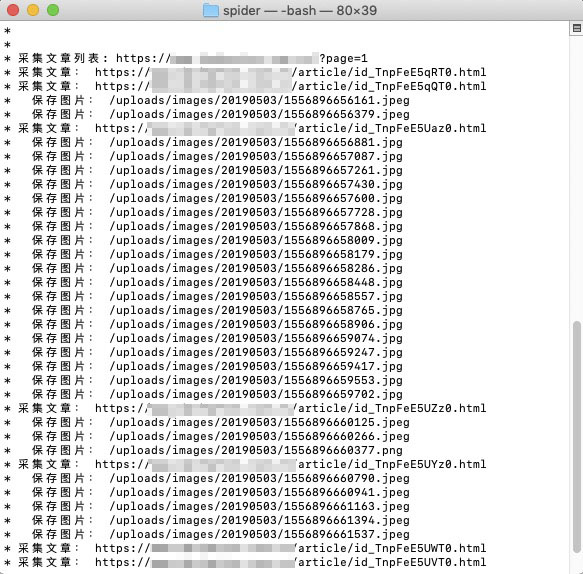
重写了爬虫,程序逻辑如下:
1,爬虫抓取文章列表第一页。
2,获取文章列表。
3,遍历文章。
4,把文章列表中文章的缩略图下载保存。
5,把文章内容中的图片全部下载保存,并用图片新路径,替换文章内容中的图片地址。
6,保存文章内容到数据库。
7,处理完文章列表后,递归执行下一页文章列表。
var http = require('http');
var http = require('https');
var fs = require('fs');
var cheerio = require('cheerio');
var pool = require('./mysql_pool.js');
var domain = 'https://www.test.com';
var url = 'https://www.test.com/?page=';
var page = 1;
var total = 578;
main();
async function main() {
// 获取文章列表
var list_url = url + page;
console.log("*\n*\n*\n* 采集文章列表:", list_url);
var list_html = await getHtml(list_url);
var list = await getList(list_html);
// 处理文章内容
for(let article of list){
console.log("* 采集文章:", article.url);
let html = await getHtml(article.url);
let arc = getArticle(html);
// 完善采集的文章各个字段
arc.thumbnail = article.thumbnail;
arc.description = article.description;
//如果有缩略图或图片需要下载,先创建当天日期的目录
let image_arr = getImageArr(arc.content);
var date = new Date();
var y = date.getFullYear();
var m = (date.getMonth()+1 < 10 ? '0'+(date.getMonth()+1) : date.getMonth()+1);
var d = date.getDate() < 10 ? '0'+date.getDate() : date.getDate();
var dir = "/uploads/images/images/" + y + m + d;
if(image_arr.length || arc.thumbnail){
if( !await getStat('.'+dir) ){
await mkdir('.'+dir);
}
}
// 处理文章内容中的图片
for(let img of image_arr){
var new_img = await downloadImage(img, domain, dir);
arc.content = arc.content.replace(img, new_img);
}
// 处理文章缩略图
if(arc.thumbnail){
arc.thumbnail = await downloadImage(arc.thumbnail, domain, dir);
}
// 把采集信息存入数据库
let insert = await insertArticle(arc);
if(!insert){ console.log("* 保存失败"); }
}
// 递归处理文章列表
if(page++ < total){
main();
}else{
process.exit(0);
}
}
// 获取指定页面 HTML
function getHtml(url) {
return new Promise(function(resolve, reject){
http.get(url, function (res) {
var html = '';
res.on('data', function (data) { html += data; });
res.on('end', function () {
resolve(html);
});
}).on('error', function () {
console.log("获取列表失败:", list_url);
reject(data);
});
});
}
// 解析文章列表HTML
function getList(html) {
var $ = cheerio.load(html, { decodeEntities: false });
var items = $('.media');
var list = [];
items.each(function (arg) {
var item = {};
item.title = $(this).find(".media-heading a").text();
item.url = $(this).find(".media-heading a").attr("href");
item.url = domain + item.url;
item.thumbnail = $(this).find(".article-thumbnail").attr("src") ? $(this).find(".article-thumbnail").attr("src") : "";
item.thumbnail = item.thumbnail.replace("\\", '/', item.thumbnail);
item.description = $(this).find(".word-2-line").text();
list.push(item);
});
return list;
}
// 解析文章页HTML
function getArticle(html) {
var $ = cheerio.load(html, { decodeEntities: false });
var article = {};
article.title = $(".col-md-8.col-md-offset-2.margin-to-50 h2").text();
article.content = $(".article-content").html();
article.content = article.content.trim();
return article;
}
// 获取文章页中图片的 url 地址
function getImageArr(str){
var pattern = /src=[\'\"]?([^\'\"]*)[\'\"]?/gi;
var img_arr = [];
var img_obj = [];
while(img_obj = pattern.exec(str)){
img_arr.push(img_obj[1]);
}
return img_arr;
}
// 下载图片
function downloadImage(url, image_domain, dir){
return new Promise(function(resolve, reject){
// 处理图片url
url = url.replace(/\\/g,'/');
let url_head = url.substr(0,2);
if(url_head != "ht" && url_head != "//"){
url = image_domain + url;
}
// console.log("* 下载图片:", url);
// 图片地址
let suffix = url.slice(url.lastIndexOf(".")+1).toLowerCase();
var image_url = dir + "/" + Date.now() + "." + suffix;
console.log("* 保存图片:", image_url);
// 下载图片
http.get(url, function(res){
var imgData = "";
res.setEncoding("binary");
res.on("data", function(chunk){
imgData+=chunk;
});
res.on("end", function(){
fs.writeFile("." + image_url, imgData, "binary", function(err){
if(!err){
resolve(image_url);
}
reject("图片下载失败!");
});
});
});
});
}
// 读取路径信息
function getStat(path){
return new Promise((resolve, reject) => {
fs.stat(path, (err, stats) => {
if(err){
resolve(false);
}else{
resolve(stats);
}
})
})
}
// 创建路径
function mkdir(dir){
return new Promise((resolve, reject) => {
fs.mkdir(dir, err => {
if(err){
resolve(false);
}else{
resolve(true);
}
})
})
}
// 保存文章到数据库
function insertArticle(arg) {
return new Promise(function(resolve,reject){
var data = [];
data.push(arg.title);
data.push(arg.thumbnail);
data.push(arg.description);
data.push(arg.content);
data.push(parseInt((new Date()).valueOf() / 1000));
var sql = "INSERT INTO t_article(name, thumbnail, description, content, create_time) VALUES (?,?,?,?,?)";
pool.query(sql, data, function (err, results, fields) {
if (err) throw err;
if(results.insertId > 0){
resolve(true);
}else{
reject(false);
}
});
});
}
修改时间 2024-05-29
声明:本站所有文章和图片,如无特殊说明,均为原创发布,转载请注明出处。